|
I am a Co-Founder and CEO of Kotoba Technologies, Inc. Previously, I graduated from CS Ph.D at Cornell University in 2023, where I was advised by Yoav Artzi. I am grateful that My Ph.D. study was supported by Cornell Hopcroft Fellowship (2019-2020) and Masason Fellowship (2020~2022). I was a Research Scientist Intern at Hugging Face in summer 2022, working with Sasha Rush. and Victor Sanh; I was a Research Specialist at Princeton University in 2019, working with Jia Deng; I did my undergraduate at the University of Michigan from 2015 to 2018 with B.S.E in Computer Science where I worked with Jia Deng, Rada Mihalcea and Dragomir Radev; I was a Software Engineer Intern in the Facebook Applied Machine Learning team in summer 2017, where I was supervised by Juan Pino. Email / Google Scholar / LinkedIn / Twitter |

|
|
I'm interested in natural language processing, computer vision, and machine learning. One of the core topics in my research is about how to learn grounded language systems thorugh interactions with human users. Representative papers are highlighted. |
|
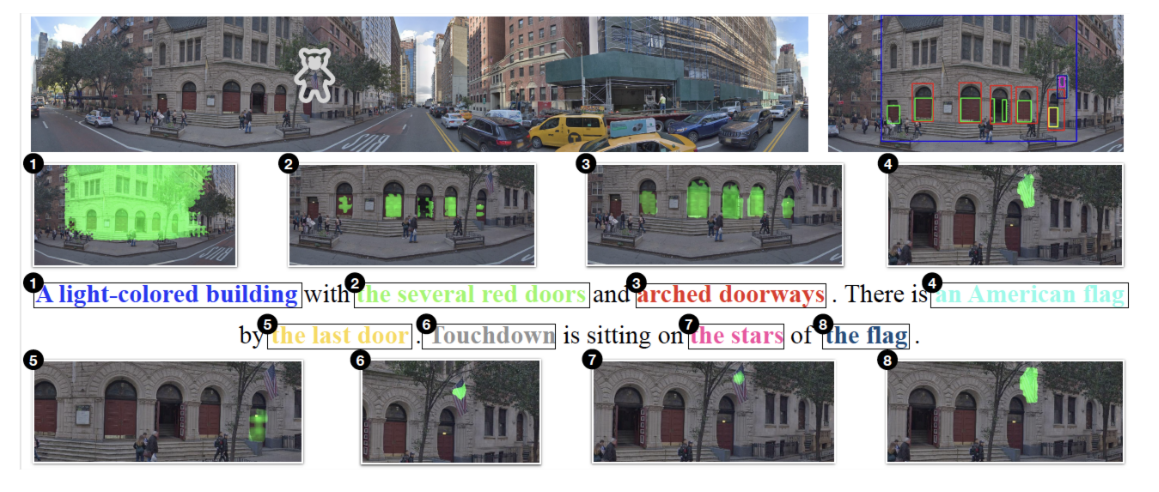
Noriyuki Kojima, Hadar Averbuch-Elor, Yoav Artzi TMLR, 2024 arXiv / code Presenting a framework to jointly study vision and language tasks and the fundamental steps of phrase grounding. |
|
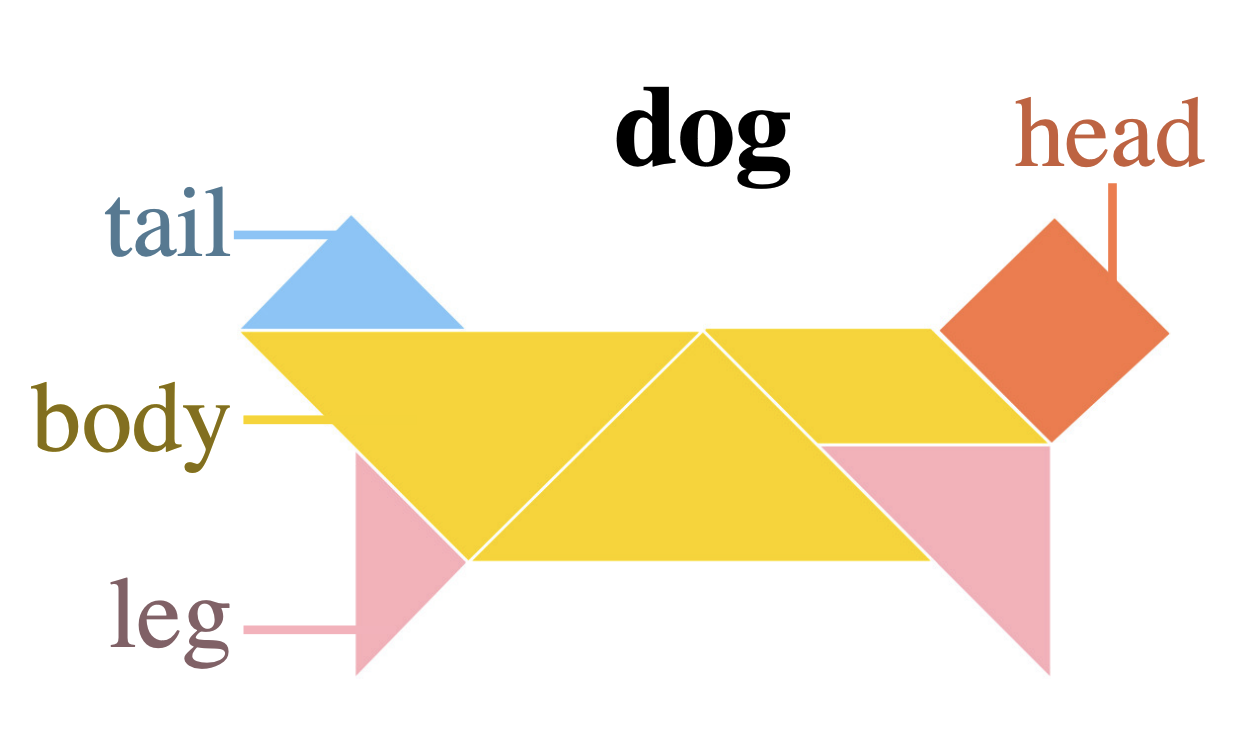
Anya Ji, Noriyuki Kojima, Noah Rush, Alane Suhr, Wai Keen Vong, Robert D. Hawkins, Yoav Artzi EMNLP, 2022 (Best Paper Award) arXiv / code Presenting KILOGRAM, a resource for studying abstract visual reasoning in humans and machines. |

|
Anne Wu, Kianté Brantley, Noriyuki Kojima, Yoav Artzi ACL, 2023 project page / arXiv / code Presenting a new benchmark for language-conditioned reinforcement learning in visual environments. |

|
Yuntian Deng, Noriyuki Kojima, Alexander Rush ICLR, 2022 demo / arXiv Studying diffusion models for markup-to-image generation. |
|
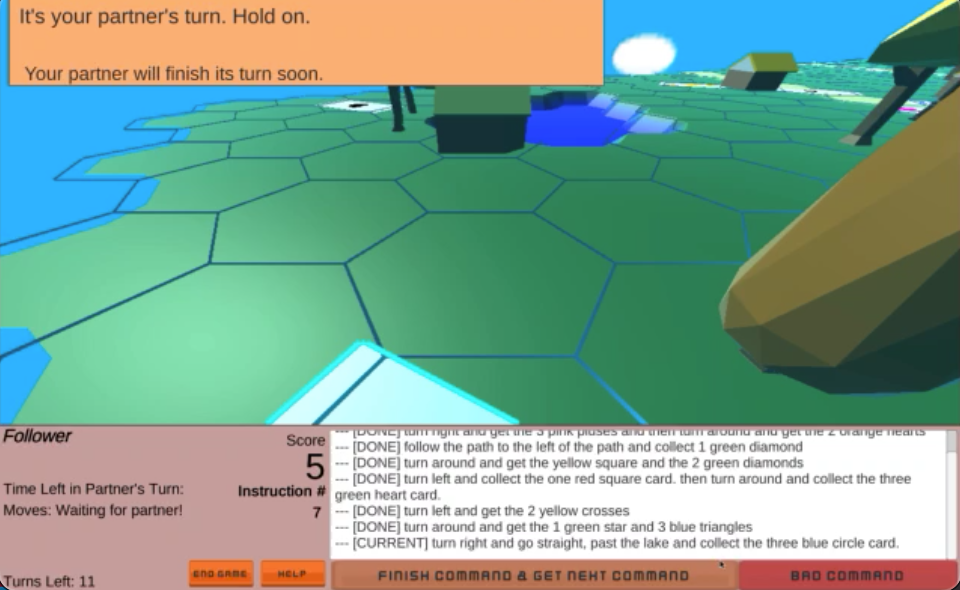
Noriyuki Kojima, Alane Suhr, Yoav Artzi TACL (presented at EMNLP), 2021 (Oral) project page / arXiv / video / code Studying continual learning for natural language instruction generation by observing human users' instruction execution in a collaborative game. |

|
Noriyuki Kojima, Hadar Averbuch-Elor, Alexander Rush, Yoav Artzi ACL, 2020 arXiv / video / code Exploring what is learned by the unsupervised vision and language constituency parser via extreme simplification of model architectures. |

|
Weifeng Chen, Shengyi Qian, David Fan, Noriyuki Kojima, Max Hamilton, Jia Deng CVPR, 2020 project page / arXiv / data / code Presenting Open Annotations of Single Image Surfaces (OASIS): a dataset for images in the wild with dense annotations of detailed 3D geometry. |

|
Mahmoud Azab, Noriyuki Kojima, Jia Deng, Rada Mihalcea CoNLL, 2019 (Oral) paper / data Representing character names by adding social networks of discourse in embedding objectives. |

|
Noriyuki Kojima, Jia Deng Preprint, 2019 arXiv Comparing learning-based methods and classical methods for navigation in virtual environments. Classical methods > learning-based methods in high-level, but learning-based methods learned useful regularities. |
|
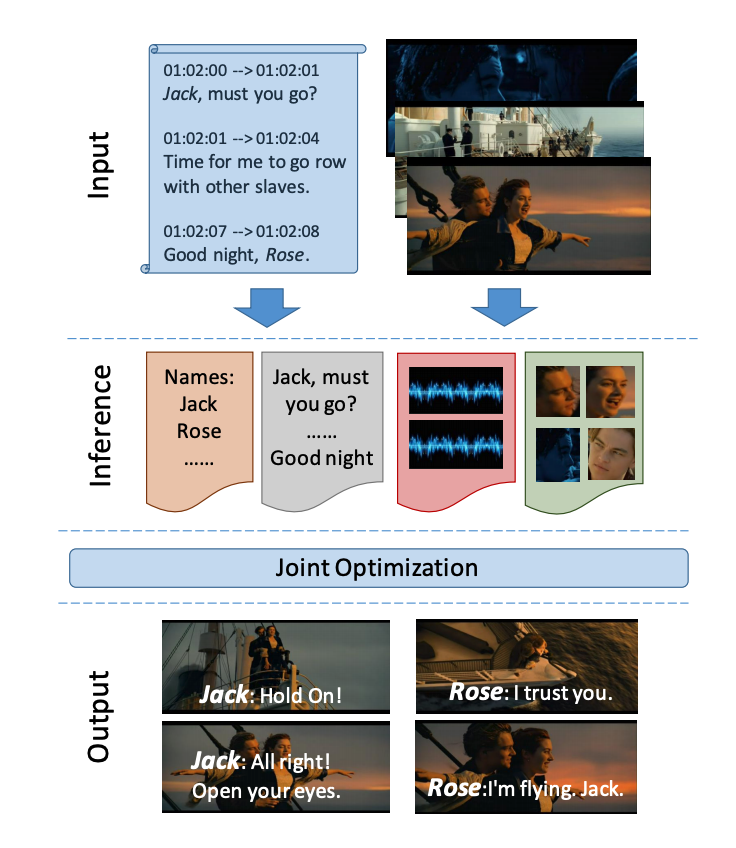
Mahmoud Azab, Mingzhe Wang, Max Smith, Noriyuki Kojima, Jia Deng, Rada Mihalcea NAACL, 2018 arXiv / poster / data Proposing a new model for speaker naming in movies that leverages visual, textual, and acoustic modalities in an unified optimization framework. |

|
Mingzhe Wang, Mahmoud Azab, Noriyuki Kojima, Jia Deng, Rada Mihalcea ECCV, 2016 paper / poster / code Proposing structured matching of phrases and regions that encourages the semantic relations between phrases to agree with the visual relations. |
|
|
 |
Reviewer: ACL2020, NAACL 2021, ACL2021 (Outstanding Reviewer), ACL Rolling Review 2021 - 2022 and so forth
Program Committee: 2nd Workshop on Advances in Language and Vision Research (ALVR) |
|
Last updated: August 2021 |